|
Programming a Virtual File System - Part I by (05 July 2001) |
Return to The Archives |
Introduction
 |
|
When I started designing my new 3D Engine, I realized that I needed some kind of
file system. Not only some file classes or so, but something I call a Virtual File
System (VFS), my own file system that supports nice features like
compression, encryption, fast access times, and so on. So I decided to publish my efforts so that you don't have to re-invent the wheel (as we say in Germany...;-) This Article Series will consist of 2 Parts. The first one is the one you're reading at the moment, and it will handle the Design and Interface of the VFS. The second Article will discuss the entire implementation (this will be the larger one). I'd really appreciate comments and constructive critics from you at michiwalter@gmx.de to improve the VFS. |
|
What Is The VFS And The VFS Library?
|
| The VFS is a File System, similar to the ones Windows uses (like FAT32, NTFS, ...).The main difference between the VFS and a real FS is that the VFS uses the real FS within its implementation. Our VFS Library is a collection of Functions, Structures and Tools, with which you can create and work with VFS. |
|
The Features
|
Now we'll try to name some features of the VFS:
Now since we have set up our Features Table, we can advance to the Design Phase. |
|
Basic Design
|
|
Ok, let's start playing a little bit around with the design. At first, I
designed a full-OOP, Interfaces- and Class-Factory using approach, but I
realized that it overcomplicated the interface ( anyway if you're interested in
this approach just drop me an e-mail at michiwalter@gmx.de). The other idea is
the following which may look similar to you if you already used FMOD ( because
of the function naming conventions ). Let's start now: First, we have the main Interface of the VFS with 16 Functions. I'll present you these Functions first, then I'll discuss what they are for and in the next article we'll discuss the implementation, okay ?
These Functions don't do really more than setting up / freeing some internal Structures we will need in the Implementation. |
|
Filters
|
Well, that's a little bit harder now. a VFS_Filter is a kind of subprogram that processes data. You could for instance write a VFS_CryptFilter which encrypts / decrypts data. You got it? A Filter consists out of something like a pre-processor ( the pfnEncodeProc procedure ) for the Data written to an archive and a post-processor ( the pfnDecodeProc procedure ) for the data read from an archive. These filters implement the concept of the pluggable compression and encryption mentioned above, because you can assign one or more Filters to each Archive File you use. If you are little confused now, then look at Figure 1 which provides a scheme diagram of the Filters. 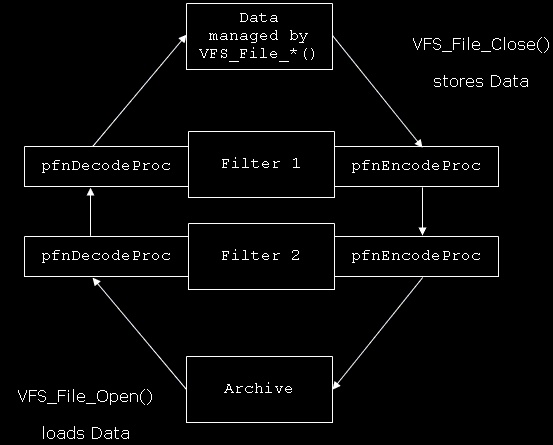 You see, the encode / decode procedures manipulate the data stream in both ways: from the archive to the memory and from the memory to the archive. For a better explanation of the Filters, let's write a simple Filter (anyway keep in mind that we won't be able test the filter, because we'll implement the VFS next week, not today). Our Filter should add 1 to each Byte.
The only sense this filter makes is to make manipulating / ripping the archive uneasier (think about how we could improve this filter, guys, perhaps with some kind of encryption algorithm or so...). |
|
The Root Path Functions
|
We discussed the root path features above, do you remember? If you don't - no
problem. I said that we want the feature to have multiple root paths, i.e.
multiple search paths like for instance the program's installation directory,
the DVD Drive and a shared Network Drive with levels. The following functions
will be created to perform this stuff:
Everything pretty basic, don't you think so? |
|
Some Other Basic Stuff
|
The next 4 functions I'll present are rather basic.
This Function will close all open archives whose reference count is 0. You may wonder why the archive files whose reference count becomes 0 aren't closed automatically, but you see, if we'd do so, we had to re-parse the Archive Files every time we load + close a File. Look at this code for a further explanation:
You see, we would have to parse the Archive File twice. With the VFS_Flush()-using solution, we have only to reparse once. A good place to call VFS_Flush() in a Game might be when all Level Data is loaded. But now the last 3 Basic Functions:
OK. First, we have to define the expression entity. For me (and for you, if you want to use the VFS), the expression entity means something like an object of the file system, like a file or a directory. The first function now checks whether an entity with the path pszPath exists. You see, that's fairly basic Stuff, but AFAIK the C(++) Standard Library doesn't contain such a function (I know, guys, they have functions like stat() but I want just something like exists() or so...). The second function is something like stat(); it returns an entity information record about the entity. The last function doesn't really have anything to do with the entity info stuff, it's just a function to return the current version of the VFS. No big deal. Nothing special (in fact, it just returns the VFS_VERSION Constant ;-) |
|
The File Interface
|
|
Now we've covered the easy stuff. But, don't worry, some more easy stuff is
following. In fact, everything covered in this part of the article is
easy. Sorry, if you want it harder, you have to wait for the next part of the
article... ;-) Well, here they are, the File Interface Functions:
There are only a few things to mention. First, the dwFlags parameter of the VFS_File_Create() and VFS_File_Open() functions can be either VFS_READ or VFS_WRITE or both, which means read access, write access or read/write access. Second, these two functions return a handle which is used by almost all the other functions as a kind of pointer. We won't use pointers but handles because they provide another layer of abstraction. If we'd use pointers we would have to specify our implementation in the interface; using handles which are just numbers provides another level of abstraction. Another thing I want to mention is the fact that our file functions will load the entire file into memory. This is necessary because of the filters feature (since they need memory to process). You can access this memory directly by using the VFS_File_GetData() function. Well, the rest is mainly stuff you'll know from the Standard I/O Library. |
|
The Library Interface
|
|
This might be the point you were expecting since some lines or better pages (and
when we talk about expecting: something I didn't expect is the fact that this is
already Page 7 or so; WOW). Anyway, let's stop babbling, here we go:
Pretty easy interface, don't you think? Just the usual stuff for an archive file. And now you finally see the application for the filter functions we saw before. You can apply filters to each archive with the VFS_Archive_Set/GetUsedFilters() functions. |
|
The Directory Interface
|
This is the last Interface of the VFS. It contains only 3 functions which are self-explanatory, I think.
Functions one and two are easy (they are like the ones for the files and the common ones in the basic interface). Number three is like the DOS dir command. Got it ;-) ? |
|
The Babbling Must Go On
|
|
That's it. We've finally finished Part I of the tutorial. I can't believe it.
But the really hard work is in front of us: We have to IMPLEMENT the VFS!!! But before I can do this, I need your ideas about the VFS. Your ideas, criticisms, recommendations, and so on... if there will be major changes to the VFS, I'll perhaps add a small Part 1b or so of the tutorial which will introduce the updates / changes of the interface (so that we'll be able to focus completely on the implementation *hehe* ) :-] The VFS header file is available for download here: article_vfs_header.h. Bye until next time, Michael Walter PS: I want FEEDBACK, Guys!!! |
|
Article Series:
|