|
Faster Vector Math Using Templates by (22 March 2001) |
Return to The Archives |
Introduction
 |
|
In the quest for knowledge we must try all kinds of new ideas. Not too long ago
I came across an interesting article written by Jim Blinn. (He is one of the
real pioneers of computer graphics. He currently works for Microsoft as a
researcher. Jim invented bump mapping, the new specular formula being used in
D3D, and so on.) He was talking about faster ways of implementing vector math
using templates and observed that the most common method of implementing a
vector class is wasteful with the stack and registers. The goal of this article
is to demonstrate these concepts and create our own implementation. You are about to embark upon one of the strangest articles you have ever read on C++. So if you are… let’s say… uncomfortable with the language, you may experience some vomiting sensations. But not to worry, after reading it a couple of times I am sure it will become clear. I will try to explain how Jim is right and how the Microsoft compiler can’t handle the truth. Well, not so much the truth as the templates, but you get the picture. |
|
Defining the problem
|
Mind you, there are many ways to do a vector class, but the most typical case is
shown in Listing 1. Let’s start analyzing this code. As you can see, the
operator + function returns a vector3d object. Of course, the return value is
placed in a anonymous temporary value on the stack. Then, the operator =
function (even if it was generated by the compiler like in our example) is used
to move the result data from the anonymous object on the stack to the final
destination. Of course, under the right circumstances, the optimizer can help
out substantially on this type of problem.
Assume we have an expression like this: vA = vB + vC + vD. How many vector3ds are going to end up in the stack? Let’s walk through step by step. The first thing that happens is that vB + vC gets executed, so that is where our first temp (call it temp1) is created. Then temp1 + vD is going to execute. This will create the temp2 object. Finally, temp2 will be copied to vA. What a waste, huh? We would much prefer that the compiler not generate any temps and refrain from reading and writing from memory unnecessarily. Listing 2a shows some pseudo assembly that demonstrates that.
But even Listing 2a is still wasteful because it uses more registers than it needs. We can improve that by using Listing 2b. As you can see only one register is used. The important concept is not really that we used only one register, but that we have done all the operations in each of the dimensions independently. The reason why this concept is so important is that when we have an expression that requires intermediate results, the compiler has a much better chance to keep everything in registers. For instance, let’s say that we have an expression that looks something like this: vA = (vB + vC) + (vD + vE). The compiler will first do vB + vC which will generate temp1, then vD + vE and create temp2 then it will add both temps (temp1 + temp2) which will generate temp3. Finally, temp3 is assigned to vA. The problem is that temp1 and temp2 exist at the same time. That means that we have 6 floats in our hands if we do all the dimensions at the same time. But if we do one dimension at a time then we only have 2 floats to deal with. The best part of this is that the method scales up very gracefully. For instance, what will happen if instead of having a vector3d we had a vector16d? If we do one dimension at a time we still have only 2 floats using the method in listing 2b. But if we do it like in listing 2a we will have 32 floats. Guess which method is more likely to use the registers efficiently. |
|
Defining the tool to solve the problem
|
|
Now that we have seen how painful it can be using the common implementation, we
must improve upon it somehow. The first thing that we will need is to define a
tool that will allow us to change the situation. I’ve chosen C++ and templates
to solve the problem. Templates still are an area of exploration. In 1994 Erwin
Unruh presented to the C++ Standards Committee a template program that generated
prime numbers. The program didn’t compile, but in its error messages it
displayed the prime numbers. This created a new way of thinking about templates. Templates are one of those kinds of things that people either love or hate. But like most things, it is what you make of it. |
|
Defining the solution
|
So how to go about solving the problem? Currently, each sub expression is
completely solved for all three components (x, y, and z) before moving on. We
are going to change the order a bit. Without regard to the complexity of the
expression, we want to completely solve for just the x component, then for y,
and then for z. (Within our studio, we call this “rotating the problem 90
degrees”.) Let’s first start with a simple formula: vA = vB + vC. The final C++
code has to expand to something like this:
Let’s first build a structure that will take our original formula and break it into a set of expressions. For that we are going to have to create a new class. This class is going to be in charge of holding one part of the formula. In this example there is only one part, specifically vB + vC, since the expression contains only 2 vectors. Actually, all the operations that we are going to deal with involve 2 or less vectors. We will call the new class vecexp_2. This class can be found in Listing 3. There are some other changes that we need to make. The vector3d class needs to be able to get each dimension in a generic way. What better way than an array of floats (see Listing 3)? Next, we are going to create an operator + function outside the class. Later on, it will become useful to have done it this way. Finally, if you keep looking at Listing 3, you will notice that we have a structure called sum. This looks a bit like overkill for what we are trying to do, but again it will make sense later on. Take your time to figure out how all this works.
Let’s now follow what happens to our original expression vA = vB + vC. First, function operator + will be called with vB and vC as references and will create a vecexp_2. Note how we call the constructor and pass both references. Those references will be stored within the vecexp_2 class when the constructor executes. After the vecexp_2 is constructed, it is passed to the vector3d function operator = because we are assigning the constructed vecexp_2 to vector3d vA. This operator = in turn calls the vecexp_2 function Evaluate for each of the dimensions. This results in the sum::Evaluate function being called. Here we call each of the vector3d::Evaluate functions and finally the results are added and returned. All this looks like overkill, but it is a stepping stone. It may seem that we just added tons more overhead to get the same thing as before. But actually, to everyone’s surprise, if the code is compiled in release mode, it will run a bit faster than the original. What happened? Well for one thing, we added tons of const’s and inlines everywhere. This caused the optimizer to inline everything, and it creates the result that we wanted in Listing 2b. Crazy isn’t it? Well, get ready for a lot more craziness. The problem with the current program is that it’s unable to handle longer expressions. To solve problems with longer expressions we need to use templates. Where do we need templates? Everywhere! Let’s try to solve a more complex problem: vA = vB + vC + vD. Our code right now will pick up vB + vC and create a vecexp_2. Note that now we could write one more function to solve this particular problem. The prototype of that function would look like inline operator + ( const vecexp& Exp, const vector3d& B ). The problem of heading this direction is that we would need a new expression class. This would cascade and require changes all over the place forcing us to add way too much code to make it practical. Not to worry, here is where we introduce the templates to solve all these problems in one shot. Listing 4 has the new source code.
Let’s first focus on the vecexp_2. Note how it takes 3 classes in the template argument, the two operands and the operator. This will allow any operator that uses two operands to use its functionality, which produces the virtual like functionality. The only requirement is that you have in your operator a function called Evaluate(int I). For this article we are only going to do the sum, but you’ll see how adding the rest of the operators are trivial. In the structure sum you will notice that it also has the same concept for the operands. We only have two types of operands so far, vecexp_2 and vector3d. Note that other classes that are not vector related could be passed to any of our generic template classes by mistake, but we will address that problem later. The other big change that has been added is in the function operator +. Now it takes two objects of any kind and it builds a vecexp_2. The syntax for all of this is a bit heavy so it may take a bit to get familiar with all this, so take your time. Congratulations if you made it this far! Now you have the basic concepts about templatized math. If you don’t understand what we just did, I don’t blame you. Just take it easy and try understanding one item at a time. Once it’s in your head, try to see how the whole thing works.
Okay, now we can solve any type of expression that involves additions with other vectors. Fantastic! Let’s push it a bit more and try to do it with two types, vectors and numbers. That way we can write this other interesting expression: vA = vB + 5 + (vC + vB). The first thing to consider is that the operator + will take any type. That of course includes integers, and floating point numbers, which is what we want. But the problem is that an integer doesn’t have a member function called Evaluate. This will cause our whole system to fail miserably. Well, don’t worry—it’s not that bad. We just need to add another class called vecarg. We don’t want to add complexity to the operators since we have a few more operators to write, such as *, -, /, etc. We would like to add the complexity in the vecexp_2. You can look in Listing 5 to see what the new changes to this class have been. As you see, vecexp_2 is wrapping all its types with the class vecarg. The vecarg class creates a generic template for all types. You will notice that inside the class it also has a member function called Evaluate. Again, this forces any type to have that function. This is a good thing since this class will solve two problems. The generic version of it still assumes that the basic type has a function called Evaluate. We want to do that because it will allow us to create a compile time error for any unfriendly types such our famous banana class. The second thing that it solves is that it creates a template from which we can create particular instances. Look at the other class in Listing 5. Now we have an int and a float argument with the function Evaluate. This will force the compiler to use these classes instead of the generic vecarg version. |
|
Defining the features
|
Basically we are about to finish the whole framework. We just need to clean it
up and add a few missing pieces. One detail I want to add, because I think it is
worth it, is the ability to have a multidimensional vector class. That means
that we can have a vector2d or vector4d or whatever else we want. Most game
programmers will find useful the ability to use 2D, 3D, and 4D vectors. Some of
you may even be using 6D vectors for visibility stuff. I also added another
feature just for fun, this feature will allow us to say vA.X rather than vA.V[0]
because an array like that is very unfriendly. Also, you may want 2 different
names for such things as UV vectors, versus XY vectors. Furthermore, let’s clean
up the entire thing and put it in a namespace to make sure we never collide with
any other function name. Up to the challenge? Don’t worry, this part is simple…
Take a look at the source code in Listing 6. We have changed the name of our original vector3d to base. The namespace is now called vector. One nice thing is that now vecarg, vecexp, sum, and such are hidden from the global namespace. Our base class now takes two arguments, ta_dimension and class T, which allows us to build our own personalized vectors like in Listing 7. Note that we are forced to add the operator =. This is one thing about C++ that is not helpful sometimes. It seems that our original operator is unable to make it to its children. I haven’t sat down and worked out an elegant way to solve this.
|
|
Defining the compiler workarounds
|
Okay, we’re almost done. We now need to deal with Microsoft’s C++ compiler and
make it do what we want. In our case we just want it to inline everything. For
that, Microsoft has provided a few pragmas. If we fail to force the issue the
compiler will try to be smart and fall on its face.
The first two pragmas tell the compiler to do inline recursion as deep as it needs to. You can change the depth to any number up to 255. The other pragma tells the compiler to inline whenever it feels like it. We want the compiler to inline all the functions. You would think that putting inline in front would do it, but that is not the case. The optimizer considers whether it’s worth inlining or not, which makes me wonder about the point of the inline keyword. We really need the optimizer not to think but just do. For that, Microsoft added another type of inline command called forceinline which tells the compiler to inline the functions no matter what. This almost works. I found myself having to “rebuild all” every time I compiled to force it to inline everything. Bad, bad Microsoft compiler! Finally, my last problem was that the compiler would not unroll the for loop that we introduced in the operator =. This may not be a big deal in the big picture, but it is just unacceptable for me. That is what got me madder that anything else. Well, this last problem also needs to be solved with templates. Unrolling a loop with a template requires that you put the for loop in a recursive-like form. That is not a problem most times. I had to create two different structures in order to achieve my unroll. But it’s usually good enough with just one. To keep the compiler from recursing forever, I had to add a terminator. Look at Listing 8. This function, template<> struct recurse
|
|
Examining the results
|
And now the critical question: How fast is it really? I implemented three
versions of the vector math routines. The first version is based on Jim Blinn’s
article, the second version is mine, and the last version is the common method.
The graph shows the performance on an AMDK7 950Mhz. The thing that surprised me
the most from the results was that my version worked faster than Jim’s. It has
nothing to do with the concepts, but rather how the compiler chose to inline. At
the end of the day both Jim’s version and my version should have ended up
working at the same speed, but the universe is not perfect.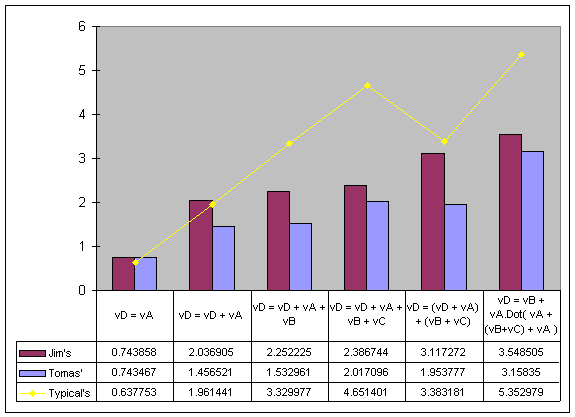
Let’s take a quick look at some of the assembly generated by each of the versions. You will notice that Jim’s code is actually the longest, yet it performs better than the standard method. The compiler produced code which stalled less than the common implementation. It accomplishes this by interleaving the moves and the floating point operations. You can still see how much movement of memory there is due to poor inlining. My method had some memory movement, but far less than either of the other two versions. The common method fails to inline as much as it should, and spends most of its time moving memory from the floating point unit. Although performance may vary with different compiler options, Jim’s and mine should most often produce better code. |
|
Limitations
|
|
In a statement like vA = vB + vC, each component of vA can be expressed using
only one component each from vB and vC. However, assume we have a cross product
function and the following: vA = Cross( vB, vC ). There is no way to express,
say, vA.X using only one component from vB (or from vC). This last one isn’t
too bad. But it can get much worse. Consider: vA = Cross( vB1+vB2, vC1+vC2 ).
The two vector adds should need 6 floating point additions total, and the cross
product itself needs 3 subtractions. But beware! A naďve implementation of the
cross product using these techniques could very well end up performing 12
floating point additions and 3 subtractions. Dot products can also lead to
trouble. I the source code included with this article there is an example on how
to implement the Dot product properly. A colleague of mine, D. Michael Traub, pointed out, it gets even worse if you extrapolate these techniques to matrices. Consider matrix concatenation: mA = mB * mC. The upper left cell of mA can only be expressed by using 4 components each from mB and mC. Of course, matrix transposition does not have any problems since each cell of the transposed matrix is expressed as one cell from the original matrix. It’s just not the same cell. These techniques work best when each component of the resulting vector can be expressed entirely in terms of only one component per vector in the expression. Operations which are troublesome should just do it the old fashioned way and fully compute their result to be stored internally. Our clever “solve completely for each component at a time” pipeline will be forced to stall on these operations, but it certainly beats redundant computations. |
|
Conclusion
|
|
Well, we have learned to take a simple math vector class and transmute it into a
mean parsing machine. With three dimensional vectors, we realized performance
improvements of up to 2.3 times over the typical implementation. There should be
even larger gains with vectors of higher dimensions. (Note that there was no
attempt to implement template versions of matrix operations, so we don’t know
where that may lead or what performance changes may be realized. Said
differently, the matrix version is left as a reader exercise!) As cool as this all sounds, it has its place. There are many issues with using templates. Most compilers still don’t completely satisfy the standard C++ language description. This can cause incompatible code, not to mention obfuscated bugs. There is the issue with the optimizer and the inlining. Not all compilers can do this in a very elegant way. The Microsoft compiler wouldn’t inline everything unless I rebuilt the entire project. There are also the new SIMD instructions in the new processors which provide an attractive alternative to using standard floating point math for our vectors. But all is not lost. We have learned how to think in a different way using templates. We can apply our new knowledge to many other problems such as AI, physics, or even file processing. As always, it is up to you to decide whether this new tool is the right thing for a particular problem. So pick and choose your battles carefully, because there are two times you need to deal with: run time and development time. Download the source code included with this article: article_fastervectormath.zip |
|
References
|
|
Tomas Arce www.zen-x.net Jim Blinn Jim Blinn’s Corner. Optimizing C++ vector Expressions IEEE Computer Graphics Applications www.research.microsoft.com/~blinn/ Pete Isensee Fast Math Using Template Metaprogramming Game Programming Gems |
|
|