|
Improving Software Performance by (26 July 1999) |
Return to The Archives |
Introduction
 |
|
Regardless of any programmer’s experience and
expertise, there is always a potential for performance improvements.
Performance critical software should always be analyzed for bottlenecks
and poorly written code. The following information is part guide and part description of my recent experiences tuning my landscape renderer. Since it is hard for me to tell you how to tune and improve the performance of your software, hopefully my real world examples will give you some ideas about what to look for in your own software. |
|
Never Fly Blind
|
|
It is virtually impossible to properly optimize software without
the proper tools. Given the complexity of today’s CPUs and the sophistication of the
optimizing compilers, many times there is little correlation between what we think is
optimized code and what performs well. Without the proper tools, gross performance goofs
and minor tweaks can go totally unnoticed. When looking for a performance analyzer, there are a few things that you should try to get: Time base sampling is where the analysis software gathers data about the current PC at a high incidence regular interval. This form of analysis provides the most telling information about which routines, source lines and instructions are consuming the most CPU. Call graph profiling gathers information about which routines are calling what routines and how many times they are doing it. Call graph profiling helps in determining if CPU stress can be reduced by reducing the number of times a routine is being called. Coverage analysis helps in locating routines or code paths that are not being tested by the test plan. Coverage analysis helps to make sure that all code is properly tested and profiled. Instruction cache analysis provides information about when an instruction crosses a cache line boundary and thus requires two cache lines. This analysis is helpful in spotting places where the instruction stream is stalling the CPU by using both the cache lines. Quality reporting and views is a must. Microsoft’s profile tool that comes with Visual C++ does a good job a collecting routine based sample information, but the reporting tools are so poor that it makes the package useless for any serious profiling. After looking at a few performance analyzer packages, I settled on Intel’s Vtune package. I have yet to find any coverage analysis tools in it, but I haven’t really looked yet. The UI is a little clunky, but it does the job. |
|
Software Performance Basics
|
|
When
analyzing the performance of software, there are a few things that are important to remember. Use a stable test plan. The only way to properly compare the results of one test against another is to make sure that the test is the same. For my application, my software took a predetermined path through the landscape. Also, make sure that you are always running the same set of applications during the test. It is best just to not run any other applications on the computer while testing is in progress. Performance analysis is a process of diminishing returns. When you first start tuning your application, you will likely see significant improvements with little effort. However, as you continue, the effort will skyrocket and the results will plummet. Only change one thing at a time. Given the dual cache instruction stream and the L1 and L2 memory caches, a single change in one part of the program can have significant effects on other parts of the program. If you keep your changes down to 1 change per test, then you will know exactly how that change affected the whole program. |
|
Gross Performance Problems
|
|
Usually,
when you first start doing performance analysis, you will see some gross performance
problems. Such things as bugs, bad programming, and changing requirements can cause these problems. Example: When I first started analyzing the performance of my landscape renderer, a routine called PreNormalMultiply was taking up 7% of the CPU (time based sampling). This routine takes a normal vector and a matrix and multiplies them. PreNormalMultiply is similar to the routine PreMultiply that takes a vector and multiplies it by a matrix. The difference between the two is that PreNormalMultiply does not include the translation part of the matrix in the multiplication. What was so strange was that PreNormalMultiply should have only been called for each face in the landscape while PreMultiply should have been called for every vertex. Since PreMultiply was only consuming 3% of the CPU, it was obvious that something was wrong. I ran a call graph profiling session on the program and found that PreNormalMultiply was being invoked 1.5 million times while PreMultiply was being invoked only 0.3 million times. 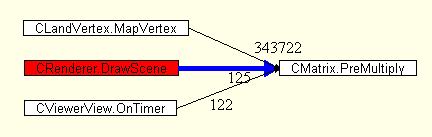 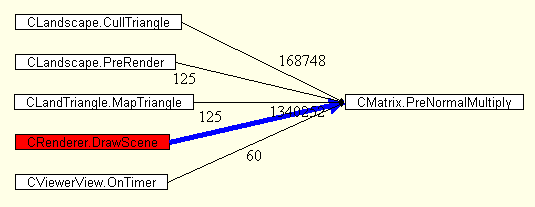 After reviewing the code three things became obvious. First, PreNormalMultiply was actually being called twice for every face in the landscape (bug, pure and simple). Second, since the landscape is stored as a binary triangle tree, PreNormalMultiply was being called for landscape faces that were not leafs and thus would have never been rendered. Third, PreNormalMultiply was being called for faces in the landscape even if they were culled from the frustum. Since the PreNormalMultiply was only being used for backface testing, there was no reason to invoke the routine for culled faces. After both these problems were fixed, PreNormalMultiply was using only about 2.5% of the processor. |
|
Blowing the L1 and L2 Cache
|
|
As the amount of data being rendered increases, performance
becomes more and more dependent on how the data is organized. It is a common
practice to store shared information separate from the data using that information.
This is especially true when operations on that shared data can be costly.
Operating on the shared data instead individual copies can save large amounts
of CPU time. However, if the shared data becomes too disjoint in memory from
other data, the chance of blowing the L1 cache greatly increases. Example: In my landscape renderer, the triangles are stored in one data structure while the actual vertex data is stored in separate structures. This greatly reduces the number of matrix multiplications and frustum tests. Triangles are processed in two phases, the map and cull phase and the level of detail (LOD) phase. In the map and cull phase, vertices are mapped to the eye space and tested against the frustum. In the LOD phase, eye space errors are recomputed and triangles are either split or merged. In an early version of the renderer, the error computation routine was taking 36% of the processor. Over 11% of the time was spent computing the mid point of the hypotenuse of the triangle.
After looking at other instructions in the same routine, it became clear that the amount of CPU being taken by the mid point computation was far greater than what normally should be consumed. The problem was that the indirections used to access the two vertices were accessing memory not in the L1 cache. This caused massive delays for the processor. To resolve this problem, I decided to move the computation of the mid point to the map and cull routine and store that value with the triangle. By moving the computation there, I was accessing memory that was already in the L1 cache. Even though this increased the size of the triangle structure by 4 bytes and caused the mid point computation to be executed for every triangle instead of just the split or merge candidates, performance improved by 7-8%. |
|
Hoist Semi-Constant Computations to Higher Levels and Don’t Do Unnecessary Work
|
|
When
programming, it is very easy to use canned routines to do computations without
realizing how much overhead can be involved. Many times a generalized version of an
algorithm is used because of availability instead of creating are more specialized
version that better fits the specific need. Even though creating large numbers of
specialized routines is bad programming style and a maintenance headache, strategic
use of specialized routines can greatly improve performance in high stress code. Example: Part of the error computation in the landscape renderer was taking the vertical error in a triangle and mapping it to screen space. This would result in a user based physical representation of the error. To compute the error, I used the following code:
Even though the code is technically correct, it wastes so much CPU time that the programmer should be shot. One of the first optimizations was to remove the g_sModelToEye matrix. Since I only had data in the z coordinate, there was little reason to multiply 2/3s of the matrix by zero.
Next, since the projection matrix only really had 3 real multiplications in it. There was little point in using a matrix. In the following code, g_vProjection is the 3 elements of the projection matrix that perform the math we need.
The final optimization was the realization that for a given frame, g_sModelToEye and g_vProjection were constant for the landscape. Since g_vProjection was computed specifically for the landscape, I pre-multiplied the matrix by the projection at the start of the frame rendering. This resulted in the following code.
In the end, 25 multiplications and 15 additions were reduced to only 3 multiplications. |
|
Blowing the Instruction Caches
|
Without
a good quality performance analyzer, it is next to impossible to diagnose
instruction cache problems. However, there are some general things I noticed
when optimizing the landscape renderer. (Consult the Intel processor manual for
more accurate information and which instructions can blow the instruction cache.)Example: In the previous example code taken from the GenerateError routine in the landscape editor, the original computation for m_fBaseError consisted of the following code segment.
This code is sinful in two ways. First, m_nBaseError is computed once for the triangle when it is first created and both the CLandscape values are constants. This makes the whole expression a constant value for the life of the triangle and thus did not need to be computed every time in GenerateError. Second, m_nBaseError was blowing the cache because it was mixing floating-point math and integer math. (The floating-point math surrounded the code segment in the ComputeError routine.) To correct both problems, m_nBaseError was changed to a floating point value and the constant multiplications by the two CLandscape constants were moved to the same place m_nBaseError was being computed. The overall performance increase was around 2-3%. Here is a sample display from Vtune that show where the instruction cache is getting blown. When the vertical lines change to horizontal, or visa-versa, then an instruction used both instruction caches. You can also see the percentage of processor time that is being consumed by each instruction. (This is just a sample screenshot and has nothing to do with the previous example.)  It is important to remember that blowing the instruction cache is a normal part of the Pentium’s operation. However, in time critical, high stress routines, streamlining the code to reduce the blowing of the instruction cache can improve performance. |
|
Watch Out For _ftol (floating point to long)
|
Due to the ANSI standard, the usual code generated to convert
a floating-point value to a long includes a call, floating point processor adjustments,
and the actual conversion. To say the least, this can eat a huge amount of CPU. In the
landscape renderer, _ftol was taking almost 10% of the CPU. Following are some helper macros
that I use.
Here is a sample invocation.
This version has one major problem, it copies values to intermediate locations. However, it doesn’t have the call that the Intel web site suggested using. |
|
In Closing (a little horn tooting)
|
|
Taking
the sample dataset used by the authors of the ROAM landscape algorithm, the initial
version of my landscape renderer took 0.0360 seconds to prerender the landscape. It
took 0.0180 to render the landscape with just over 3000 triangles. Once all of the
optimizations where done, it took around 0.0200 seconds to prerender the landscape. Since
all optimizations were in the prerender phase there was little to no change to the render phase. When compared to the original ROAM algorithm, I was able to get like performance on a 450 Mhz PIII using a TNT video card. This was done with better split and merge queue management that reduced the amount of time recomputing errors to less than 5% from 36%. Also due to the split and merge queue optimizations, the performance of the routines calling ComputeError was cut by around 50%. This yielded around 5-8% overall performance increase due to less processing and less memory cache faults. Unlike the original ROAM algorithm, there was little need to implement a delayed error computation queue. However, if an delayed error computation queue was implemented to only do half the computations each frame, at least a 1% increase in speed can be expected. Another optimization, which I did not implement, was the cap on the number of splits or merges per frame. Due to some delayed split and merge operations inherent in my version of the split and merge queues, there was no need to cap these operations. However, this inherent delay caused some lesser priority splits or merges to be performed prior to the more important ones. Visually, this problem was no more noticeable than the normally popping inherent in most LOD algorithms. |
|
Related Links
|
|
|
|
|